

飛象原創(魏德齡/文)剛剛過去的2024年,新變化與新技術時刻環繞在企業身邊,“降本增效”“出海創收”“高質量發展”等成為企業在講述自身發展策略時的關鍵詞。與此同時,o1與智能體又成為伴隨AI技術演進時,被業界所更多聊起的新話題。
如今,即便是體育比賽也開始更多講求高階數據,對于企業而言,無論是發展變革,還是AI賦能,其背后都與企業對于數據資源的有效挖掘,存在著巨大關系。
發展變革與AI賦能的背后
告別粗放式發展的背后,重點在于企業正在從以往的“堆人與堆技術”轉變為對于“降本增效”的關注,背后需要創新技術對企業實現更多助力。例如,對于中國的制造業企業而言,隨著智能化轉型,將朝著提升技術含量和附加值的方向發展,智能制造、自動化、機器人技術等將成為重點。
從企業數據的發展過程中,將持續從生產數據向分析數據的過程推進。當數據在生產環節中誕生,便可能會在公有云和私有平臺上進行分配,再傳送至不同的云上,最后以SaaS模式對客戶進行服務分析。肯睿Cloudera在近期的媒體溝通會上,結合當下的市場情況給出了三個趨勢觀察結果。
當數據變得越來越多,企業在數據管理中正面臨從傳統數據倉庫向數據湖倉一體轉變的趨勢。以往分析任務可能依賴于報表系統和數據倉庫。然而,隨著業務需求對數據實時性、完整性以及對結構化和非結構化數據的支持提出更高要求,數據的重心逐漸向數據湖倉一體傾斜。
另一個趨勢是了解數據資產需要數據網格或數據編織,作為企業數據治理的重要手段,通過整合多種數據格式和語言,為數據分析和對外服務提供支持。“在跨域數據中,數據網格和數據編織為企業提供了溝通與協作的新模式。”Cloudera大中華區技術總監劉隸放描述了企業數據管理的新方向。
例如,對于存在多個不同資方的企業而言,由于數據安全性和復雜的股權結構,數據的歸屬和跨域使用問題變得突出,數據網格理念尤其是在面對不同資方,以及解決跨部門、跨架構的數據協作問題上,提供了“以數據為產品”的有效對話模式。
第三個趨勢在于人工智能應用生命周期需要可信數據。企業成功應用AI的關鍵在于從0到1的積累過程。“企業不要去羨慕市場上的生成式AI有多火,要先把馬步扎實。”劉隸放專門在媒體會上強調了企業數據資產文化積累的重要性。
例如,在大語言模型大熱之前,許多企業已具備成熟的數據資產和相關文化,如OCR系統、智能客服等。沒有這些基礎,僅依賴現成模型難以實現真正的突破。在AI應用中,數據不僅是支撐技術的基礎,更是企業構建獨特競爭力的核心。結構化和非結構化數據的組織能力以及對數據資產的深度利用,決定了企業能否從AI中獲得實質性價值。
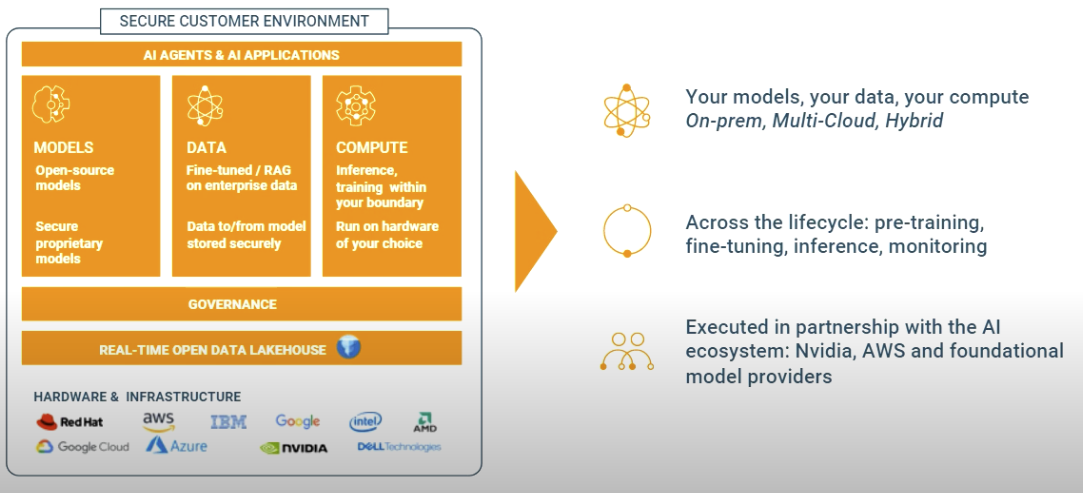
Cloudera也正在順應上述市場環境趨勢需求,為AI提供一個集中可信的數據中心,為模型和平臺的構建提供堅實的數據基礎。Cloudera不僅支持在公有云和私有平臺上的AI部署,還注重跨平臺能力,推動現代化數據架構的發展,實現數據和應用的無縫連接。
務實AI策略與數據管理挑戰
面向2025年,Cloudera發布了五大科技趨勢預測。揭示了在未來一年生成式AI和AI Agent等創新技術的發展趨勢。其中包括生成式AI的應用將趨向務實,AI Agent將在商業決策中發揮重要作用。同時,企業面臨著AI生成數據激增的挑戰,亟需提升數據治理能力。企業需要強大的數據管理和多云策略來訪問、存儲和分析數據,從而獲取數據的最大價值,充分發揮AI潛力。
首先便是企業對于AI的態度變化,預計生成式AI熱度將減退,企業會采取更務實的AI策略。Cloudera預測,企業將不再相信生成式AI的大肆炒作,而是專注于制定與企業整體目標一致的技術投資計劃。在很多企業內部的生成式AI應用過程中,初期通常從內部知識庫問答系統入手。這種簡單應用易于實現且安全可控,可以通過開源模型和提示詞調整生成式AI結果。而一旦這一應用進行對外服務的話,就需要面臨更高的準確性和可靠性要求,一直存在的致幻率問題將會嚴重影響客戶體驗。
預計到2025年,企業將在生成式AI應用上分化為兩大陣營。一類是已成功應用生成式AI的企業,通過成熟應用實現了顯著成效,背后的核心價值在于規模化的知識獲取和洞察生成,數據質量是確保AI模型成功運行的關鍵。而另一類企業由于缺乏足夠的數據儲備,難以從生成式AI中獲得相同效益。因此他們將更傾向于采用傳統AI或確定性機器學習模型,以提升效率和生產力。
第二個預測是AI Agent將重塑商業決策,2025年將會迎來一個井噴式發展。Agentic AI正在推動創新浪潮,改變實時問題解決和決策過程。AI智能體高效優化任務,迅速應對挑戰,并實時靈活調整。這將促使企業構建事件驅動型架構,支持AI能夠及時響應現實事件,從而徹底改變電信和物流等行業。
第三是“全天候”AI為數據管理帶來新挑戰。以某國內制造業企業為例,該企業將電池信息的收集頻率從每小時一次提升到每幾分鐘一次,顯著增加了數據的實時性和精準性。但數據量的爆發也帶來了存儲和分析方面的挑戰,需要更高效、更廉價的存儲解決方案。企業面臨算法優化和數據管理的多重挑戰,需結合成本控制和技術提升來實現數據價值的最大化。
當AI如同空氣無處不在,滲透至個人生活的方方面面。面對數量龐大且種類繁多的AI生成數據,企業如何從中挖掘出有價值的信息,成為亟待解決的問題。企業努力從不斷增長且種類繁多的AI生成數據中獲取洞察力,糟糕的數據管理可能會導致企業被信息流淹沒,難以有效地利用這些數據資源。為了充分釋放AI潛力,企業需要強大的數據管理和多云策略來訪問、存儲和分析數據,無論數據是在本地、云中還是在邊緣,都能提煉獲取數據的最大價值。
這也引出了下一個預測內容,當企業在2025年致力于推動生成式AI的全面生產和規模化部署,單純的混合云架構已無法滿足企業需求。當前企業的AI算法與分析算法需要能夠跨云訪問數據,并同時追求經濟性。由于數據在公有云和私有平臺間的傳輸價格非常昂貴,企業需要平衡分布算力和數據,在利用這一環境來構建AI算法。
德勤的研究指出,企業采用生成式AI的最大障礙是合規風險和治理問題。隨著企業開始在本地或公有云中運行私有AI模型和應用,混合數據管理平臺的需求日益增長。這類平臺集成了本地與云數據源,因此具備更高的靈活性且支持更廣泛的數據訪問,在保障模型端點安全和治理的同時,賦予企業更強的控制力。
最后一個預測是私有大語言模型(LLM)將逐漸取代公有大語言模型,成為企業優選。“私有大語言模型將成為企業的優選,從合規到隱私保護,這是不可回避的趨勢。”劉隸放點明未來企業的人工智能發展過程中,將會聚焦合規與隱私需求。
預計到2025年,企業將加快定制AI解決方案的步伐,包括AI聊天機器人、虛擬助手和專屬代理應用等,以滿足特定行業或業務的需求。越來越多企業將采用企業級LLM,這將對GPU的高性能支持提出更高要求,以比傳統CPU更快的速度運行,同時確保數據管理系統具有更高的安全性和隱私保護。RAG技術將得到更廣泛的應用,將通用LLM轉化為行業或組織專屬的數據倉庫,從而為現場支持、人力資源和供應鏈等領域的終端用戶提供更加精準、可靠的數據支持。




